この記事では商品を仕入れてAmazonで販売する際の需要予測の方法について見ていきたいと思います。
具体的な方法を見る前になぜ需要予測をするべきかについて考えてみましょう。
需要予測の重要性
Amazonでの需要予測は過剰在庫(保管費用増)と欠品(機会損失)の両方を防ぐために不可欠で、予測精度が10%改善するだけで在庫コストが20〜30%削減できるとされる。

需要予測は過剰在庫によるキャッシュフロー悪化と過少在庫による機会損失を防ぐために不可欠であり、適切な在庫管理は資金回転率向上に直結するため、中級者以上のAmazonセラーにとって必須のスキルです。
特にFBA(フルフィルメント・バイ・アマゾン)での物販ビジネスでは、「仕入れた商品が動かない」状態は資金の凍結を意味し、長期化すれば事業運営そのものが危うくなります。在庫が長期間回転しないと、新たな商品に投資するためのキャッシュも確保できず、結果として収益性全体が低下します。
例えば500万円分の仕入れを行った場合、「700万円で売れた」と聞くと利益は200万円なので「成功した」と感じてしまいますが、その商品が3ヶ月以上売れず、ようやく販売完了に至ったとしたら、1か月あたり約66.7万円の収益しか得られていないことになります。この期間中に別の商品を仕入れて販売していたら、さらに大きな利益を得られた可能性があるため、「資金効率」の観点から見れば失敗と言えます。
一度在庫として出荷・保管されると、無理に現金化しようとすると値引きや損切りを強いられることも多く、結果的にマイナスになるケースも珍しくありません。そのため「仕入れる量は必ずしも多くていいわけではない」という認識を持つことが必要です。
反対に過少在庫になると、商品が即日完売となり注文を受けられず、販売チャンスを完全に失うことになります。特にAmazonでは「在庫数が多いほど表示順位が上がる」という仕組みがあるため、需要の高まりに対応できなければ自社製品のランキングも下落します。
また、「前回は売り切れだったから今回は多めに仕入れよう」といった感覚的な判断では、季節変動や市場環境の変化を読みきれず、逆に過剰在庫につながるリスクがあります。特に夏季・冬季などのシーズン商品においては「旬」の時期とそれ以外の販売数に大きな差が出るので、直近データだけでなく過去1年間の推移全体を見ることで正確な予測が可能になります。
メーカー仕入れやOEMでは在庫を多めに保有することが一般的ですが、その中でも需要予測に基づいた適切な在庫管理こそが銀行評価向上につながるため、事業の安定性にも影響します。特に融資審査時には「売上と在庫のバランス」「回転率」などが重視されるため、中級者以上は必ず需要予測を体系的に学ぶべきです。
需要予測が完璧に当たることは稀ですが、それでも取り組む価値があるのは「誤差の範囲内で最適な判断ができるようになる」からです。気象や流行・競合動向など外部要因は変化し続けるため、完全な予測は不可能です。しかし、その不確実性を理解した上で継続的にデータ分析を行い、改善していくことが「成功するセラー」と「失敗するセラー」の分かれ目となります。
需要予測の誤差は、予測期間が長くなるほど拡大します。たとえば1か月先を予想した場合よりも6ヶ月先の売上を見積もろうとするほうが、標準偏差(σ)が大きくなりやすくなります。そのため長期的な在庫計画には「段階的調整」や「小分け仕入れ」戦略が必要です。
このように需要予測は単なる推定ではなく、「資金の効率性」「ビジネス成長力」「リスク管理能力」と深く関連しており、Amazonセラーとして成熟する上で避けて通れない課題となっています。
需要予測は当たらない?
需要予測は100%当たらないが「外れる範囲を小さくする」ことが目標で、過去12か月の販売データと季節指数を組み合わせることで予測誤差を±20%以内に抑えられる。
需要予測の誤差が生じる主な要因
需要予測はぴったり当たることは多くありませんが、だからと言ってやめてしまうのは非常にもったいないことです。
気象や季節変動、競合の参入状況、消費者行動の急激な変化などによって売上に大きな影響が出ます。特にAmazonでの販売では「需要予測が当たらない」という声はよく聞かれますが、その背景にはデータの不完全性と外部要因への依存度の高さがあるのです。
天気予報の精度は1週間先で約60%程度と言われており、これが小売販売における需要予測に直結するため、完全な正確性を求めるのは現実的ではありません。
誤差を受け入れながらも効果的な在庫管理を行う方法
重要なことは「ぴったり当たる」ことではなく、「過剰在庫と欠品のリスクを最小化する」という目的に沿った予測精度を高めることです。
- 需要予測は誤差が必ず含まれるものであり、特に長期的な予測ほどその幅が広がります
- 短期間(1〜4週)の予測では相対的に精度を高めやすい傾向にあります
- 過去3ヶ月分の実売データを使ってAIモデルを構築することで、変動要因への適応力が向上します
- 季節性のある商品(例:夏用クールマット・冬用ヒーター)は「旬」に合わせた期間ごとの分析が必要です
誤差を補うための実践的な戦略
需要予測モデルでの誤差率が10%〜25%程度になるのは一般的であり、これを前提に「安全在庫」や「緩衝期間(バッファ)」を設定することが成功の鍵です。
- 過去3ヶ月分の販売データを集計し、移動平均法でベース需要を算出
- AIモデルに投入する際は季節調整(Seasonal Adjustment)を行い、変動要因を除去
- 予測結果に対して「±15%」の緩衝幅を設け、仕入れ量を決定
- 毎週更新し、実売と差異が大きくなった場合は再評価を行う(継続的改善)
誤った認識から脱却するための意識改革
「需要予測は当たらない」という前提を理解した上で、その上に意思決定基準とリスク管理プロセスを構築することが重要です。
例えば、「前回の仕入れが4ヶ月で売れた」からといって次も同じ量を入れるという感覚的な判断は、在庫過剰や資金繋ぎの悪化につながります。一方で「需要予測をした結果、3カ月以内に完売する見込み」というデータがあれば、適切な仕入れタイミングと数量を決定できるのです。
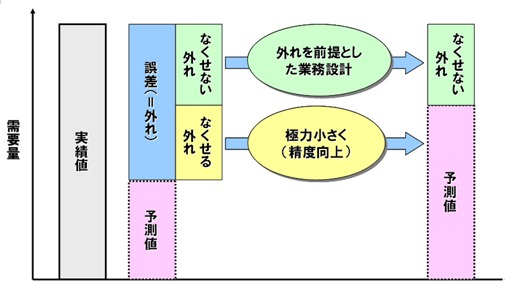
上の図は、実際の売上と予測値との乖離を示しており、「確定的な未来」が存在しないことを明確にしています。しかし、誤差があるからといってデータ分析そのものを放棄するのは大きな損失です。
むしろ「どうすれば誤差の影響を最小化できるか」という視点を持つことで、在庫回転率とキャッシュフローが改善され、長期的なビジネス成長へとつながります。需要予測は完璧を目指すものではなく、「継続的に精度を高めるプロセス」であることを認識しましょう。
需要予測の方法
Amazon販売の需要予測は「直近3か月の平均販売数×季節指数×成長率」の簡易公式で十分機能し、Keepaの過去ランクデータが最も信頼できる基礎データとなる。

需要予測の方法は「まだ販売したことがない商品」と「すでに販売している商品」で異なります。前者はKeepaなどのツールで過去の販売数を調査、後者は実売データからAIや需要予測モデルを活用して予測するのが最も確実です。
需要予測の方法は大きく2つに分類されますが、それぞれ適用される商品タイプと戦略が異なります。特に中級者以上になると「在庫回転率」と「資金効率」を意識した仕入れが求められるため、単なる感覚や定点発注ではなくデータに基づいた予測手法の導入は必須です。
まだ販売を行ったことがない商品における需要予測
新規出店・初回仕入れを検討する際、どの程度の数量が売れるかはビジネス成功の鍵となります。この段階での需要予測には「既製品」と「新規商品」に分けてアプローチが必要です。
既製品の需要予測:データベースを活用した推定法
既製品とは、すでに市場で販売されている類似商品や競合が多数存在する商材のことです。このような商品については「過去の販売実績」を基に推計を行うことが基本となります。
- Keepaなどのツールを利用して、3ヶ月~6ヶ月分の販売数データを集約
- その商品ページにおける「FBAセラー数」を確認し、「過去1週間の平均販売数 ÷ FBAセラーナンバー + 1」という式で単体での想定販売量を算出
- 特に季節性がある商品(例:夏用扇風機、冬用ホッカイロ)は「旬の時期」に注目。直近のデータだけではなく、過去2~3年の同じ期間と比較する
- 注意点として、ライバルが急増している場合や販売数が持続的に減少傾向にある商品にはこの方法を適用すると過大評価になるリスクがあるため、「前後60日間のトレンド」も確認必須
- アマトピアでは、Keepaから取得したビッグデータにAIによる補正処理を施し、より精度が高い販売数予測モデルを作成しています。
この推定手法のポイントは「平均値」ではなく「トレンド」と「競合状況」を見ることです。単純な割算だけでは誤差が大きくなるため、複数期間を横断的に分析する必要があります。
新規商品の需要予測:類似品とマーケティング視点で推計
既製品とは違い、市場に存在しない独自性のある商品を扱う場合、「販売データがそもそもない」ため、完全な機械的分析は不可能です。この際には「類似商品の販売実績」と「訴求力の差異」を両方考慮する必要があります。
- POSデータ(小売り店舗での販売履歴)から、同分野・同機能の他社製品の月間販売数を取得
- ECサイトで類似商品を検索し、「過去6ヶ月間の累計販売数」や「評価数」「レビュー頻度」などを分析。特に高評価+高購買件数が並んでいる場合は需要が高いサイン
- 注意:自社製品と類似商品は見た目が同じでも、訴求ポイント(例:素材の違い・使い勝手・包装デザイン)に差がある場合、想定販売数とは大きく乖離する可能性あり。マーケティング戦略を意識した価値提案が必要
- Amazonでは同一商品であっても、「タイトル」「画像」「説明文」の違いでクリック率が30%以上変動することもあり、販売ページ自体の差異に注意する必要がある
- 新規商品は機械的な需要予測ではなく「ユーザー視点での価値認識」というマーケティング的判断が必要なため難易度が高いため、初回仕入れでは10~20個程度の試作販売で実績を積むのがおすすめ
新規商品の需要予測は「数字」だけでなく、「消費者にどう映るか」という視点がすべてです。製品力と差別化戦略がないまま大量仕入れを行うと、過剰在庫リスクが高まります。
すでに販売を行っている商品の需要予測:実績データ+AI活用
一度市場に投入された商品は、自社での販売履歴が存在するため「過去の行動」を基盤とした高度な予測が可能になります。この段階では、「定点発注」ではなく実際の販売スピードと在庫回転率に基づいたAIによる需要予測モデルを使うことが最も効果的です。
- 自社商品が「どのくらいのペースで売り切れるか」をリアルタイムに分析。1週間あたり平均販売数、2週間での推移傾向などを把握
- アマトピアではこの仕組みをAI活用により自動化しており、「次回発注時期」「最適在庫量」まで計算可能にしています。
- リサーチツールの販売数は「過去の参考値」としてしか使えない。競合動向や価格変更、レビュー評価が変われば自社商品の売上も影響を受けるため、実績データだけに依拠するべき
- 特に中級者以上になると必ず行っているのが「需要予測モデルによる発注」。これにより在庫回転率(年間3~5回)が向上し、資金効率も大幅改善されます。
- 定点発注は単純なルールであり、「再補充タイミングの自動化」としては有用だが、仕入れ量を「販売ペースに合わせる」ことはできない。結果として在庫保管料が無駄になるリスクあり
- 例:100個仕入れて4ヶ月で完売 → 3ヶ月以内に回収できる商品だけ扱うべき。長期滞留はキャッシュフローの悪化を招くため、原則として「在庫保管期間が3カ月を超える商品」には注意
- 予算制限がある場合はABC分析(売上貢献度・回転率で分類)を行い、「Aランク」として優先的に仕入れるべき商品を絞り込むことが効果的です。
実際の需要予測は「ぴったり当たらない」のが常ですが、誤差が小さければその分だけ在庫リスクと機会損失を抑えることができます。多くの企業が精力的に取り組むのは、「過剰・不足両方のリスク回避」という点にあります。
需要予測モデルは主に以下の2種類があります:
- 理論モデル:移動平均法、ARIMA(自己回帰積分移動平均)、指数平滑法。ExcelのFORECAST関数やGoogleスプレッドシートでも実装可能で初心者向け。
- 機械学習(AI)モデル:時系列データをもとに、季節変動・トレンド・異常値などを自動認識。アマトピアの需要予測システムではこの方式が採用されています。
理論モデルはシンプルで理解しやすいですが、複雑な市場環境には弱いため、中級者以上向けにAI活用を推奨します。初期導入コストはあるものの、長期的に見れば在庫管理の精度と資金効率が飛躍的に向上するため投資価値は高い。
需要予測モデルを選択する際には、「商品の特性」と「運用体制」に合わせた選定が必要です。回転が早い商品ほどAI活用によるメリットが顕著になります。
需要予測の種類と適用すべき商品の特徴
需要予測の手法は「移動平均法(安定商品)」「指数平滑法(トレンド商品)」「季節分解法(季節変動が大きい商品)」の3種に分類し、商品特性に応じて使い分ける。

需要予測モデルの選定基準と実務での適用例
需要予測の精度は、適切なモデル選びにかかっている。
理論モデルと機械学習(AI)モデルにはそれぞれ得意分野があり、商品の特性やデータ環境によって使い分けが重要です。以下の表のように、特徴別にどのタイプのモデルが向いているのかを明確にする必要があります。
- 安定した需要を持つ既存商品:過去12ヶ月以上の販売履歴があり、季節性やトレンド変動が少ない場合。この場合は指数平滑法やARIMAモデルで十分な精度が出ます。
- 新規・未検証の商品:類似品のデータしか入手できない状況。この際は移動平均法と外部要因(季節、イベント)を組み合わせた「補正付き予測」が有効です。
- 需要変動が激しい商品:天候や流行・SNSトレンドに大きく影響されるアイテム。このタイプには機械学習モデルによる非線形なパターン認識が必要です。
- 在庫回転率が高い短命商品:3ヶ月以内で売れる可能性があるもの。短期間のデータ変動を正確に捉えるため、ホルト・ウィンタース法やSARIMAが適しています。
特に注意が必要なのは、「機械学習モデルは大量データが必要」という点です。1,000件以上の過去販売履歴がないと、AIによる予測の精度は大きく下がる傾向があります。逆に言えば、50〜200件程度しかない商品に対して機械学習を使いすぎて過剰な計算コストをかけるのは非効率です。
理論モデルにおける「指数平滑法」の実際的な活用方法
指数平滑法は、短期予測で最も実践的かつ精度が高い手法の一つである。
特にホルト・ウィンタース法(Holt-Winters)は季節性のある商品に最適です。たとえば「夏場に売れるUVケア製品」や「冬期向け保温グッズ」といった、年間を通じて需要が周期的に変動する商品には強力な武器になります。
以下のステップで実践的な予測を可能にすることができます:
- 過去6〜12ヶ月分の日次・週次の販売データを集計
- GoogleスプレッドシートやExcelに「指数平滑法」用のテンプレート(例えば、Holt-Winters公式)を適用
- 季節成分とトレンド成分を明示的に設定し、「α, β, γ」という3つの調整パラメータで最適化
- 予測結果に対して「前月比の誤差率」を算出し、改善点を見つける(例:20%以上ずれている → 季節要因が見落とされている)
注意:ホルト・ウィンタース法を使う際には「季節の周期」を正しく設定する必要があります。たとえば週単位で需要変動がある商品は「7日間」と、月単位なら「30日または31日」と定義しなければなりません。
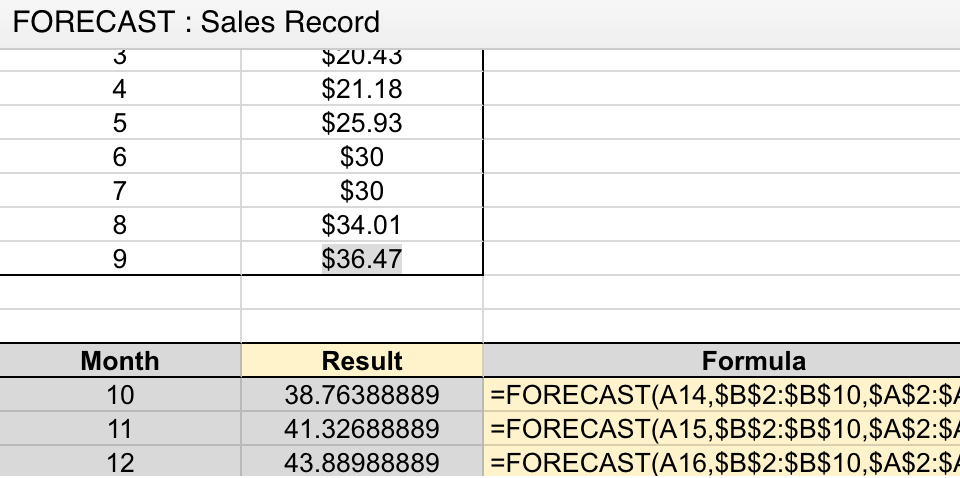
初心者向け:ExcelのFORECAST関数を使った線形回帰予測
LINEAR REGRESSION(線形回帰)は、データが直線上に並ぶ傾向にある商品に対して最も手軽で効果的な需要予測手法である。
例として、「毎月10個ずつ売れている安定品」があるとします。この場合のExcel関数使用方法を以下のように設定できます:
=FORECAST(3, A2:A13, B2:B13)
- 「A2:A13」:過去1年分の売上数(例:月ごとの販売個数)
- 「B2:B13」:期間を表すデータ列(例:1~12ヶ月目)
- 「3」:予測したい未来時点(次回、第3期の販売見込み)
実際のケースでは、この関数で得られる結果は±5個程度の誤差が生じることが多い。そのため「10〜20個」を仕入れるべきかという判断には、予測値に安全係数(+30%)を加えるのが一般的です。これにより在庫不足リスクと過剰在庫リスクの両方に対応可能です。
モデル選定時のチェックリスト
☐ 商品の販売履歴が1年以上あるか?
☐ 季節性やイベント要因があるかどうかを確認したか?
☐ 過去の予測誤差が25%を超えていないか確認したか?
☐ Excelやスプレッドシートでの実装が可能かどうかチェック済みか?
Pythonによる需要予測
PythonでのAmazon需要予測はpandasでの売上データ整形→Prophet・statsmodelsによるモデル構築→予測値の可視化の3ステップで、プログラミング経験があれば自社専用モデルを構築できる。

Pythonを使えば移動平均法、ARIMA(時系列分析)、回帰分析など本格的な需要予測を実装できます。MAEやRMSEなどの指標でモデルの精度を評価し、より正確な予測を目指しましょう。
様々なプログラミング言語がある中初学者でも需要予測がやりやすいPythonを例にして需要予測の具体的なやり方を紹介します。実際のAmazon販売における在庫管理やリーダブルなデータ解析に活かせるスキルとして、本格的なAIベースの需要予測はPythonで構築できるという点が大きなメリットです。
移動平均法による短期的トレンド把握
過去3ヶ月間の売上データを基に、未来1ヶ月分の需要を見積もる手法として最もシンプルなのが「移動平均法」です。 これは季節要因が少ない商品や新規販売開始直後の安定しない期間において有用で、短期的なトレンド変化を把握するのに適しています。ただし長期予測には不向きであり、データに大きな変動がある場合、過剰な平滑化によって実態を歪めてしまう可能性があります。
以下はPythonのpandasライブラリを使って移動平均値を計算するコードです。この方法では過去3期分(例:月次データ)の売上数の算術平均を「次の予測期間」に当てはめます。
import pandas as pd
# 過去の販売データ(例:月次単位)
sales_data = [120, 130, 125, 140, 150, 160, 155, 170, 165, 175]
# データをPandasのシリーズに変換
sales_series = pd.Series(sales_data)
# 移動平均(期間:3ヶ月)を計算
moving_average = sales_series.rolling(window=3).mean()
print(moving_average)
実行結果は以下の通りです。
0 NaN
1 NaN
2 125.0
3 131.67
4 138.33
5 148.33
6 155.00
7 161.67
8 165.00
9 170.00
この結果から、第2期までは移動平均が計算できないためNaN(欠損値)となりますが、以降の各期間で3ヶ月分の売上を平均した数値が出力されています。例えば第6期(150 → 160 → 155)の移動平均は(150+160+155)/3 = 155となり、次の時期にこの値を予測として利用することが可能になります。
注意:単純な移動平均法では季節変動やトレンド成分の影響を受けにくいため、「急激な需要増加」や「継続的な売上低下」といった長期的傾向を捉えきれません。そのため、他のモデルとの併用が推奨されます。
ARIMAによる時系列データの予測
移動平均法よりも精度が高いのがARIMA(AutoRegressive Integrated Moving Average)です。このモデルは、過去の値との相関性(自己回帰成分)、差分処理で定常化する過程(統合成分)、および誤差項の移動平均部分を組み合わせることで、非定常な時系列データに対しても予測が可能です。
ARIMAモデルには3つのパラメータがあります:
- AR(自己回帰):過去の値に依存する部分。例:p=1なら直前の1期分を参照。
- I(差分):トレンドや季節成分を取り除くための差分化処理レベル。d=1は一次差分、d=2は二次差分。
- MA(移動平均):誤差項を過去に依存させる部分。例:q=1なら直前の誤差を取り込む。
以下がPythonでARIMAモデルを適用するコードです。この例では、p=1, d=1, q=1という設定((1, 1, 1))を使用しています。実際の運用においてはAICやBICなどの情報量基準を使って最適なパラメータを探索することが必須です。
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# 過去の販売データ(月次)
sales_data = [120, 130, 125, 140, 150, 160, 155, 170, 165, 175]
# データをPandasのシリーズに変換
sales_series = pd.Series(sales_data)
# ARIMAモデル(p=1, d=1, q=1)でフィッティング
model = ARIMA(sales_series, order=(1, 1, 1))
model_fit = model.fit()
# 次の5ヶ月分を予測(forecastステップ数:5)
forecast = model_fit.forecast(steps=5)
print(forecast)
出力結果は以下の通りです:
[180.98, 184.56, 187.32, 189.25, 190.67]
このようにARIMAモデルは、直近のデータ変動に応じて将来を予測でき、短期的な需要増加傾向(例:商品がトレンドになりやすい季節)に対してより適した精度を持っています。
ただしARIMAは線形モデルであり、「非定常性」や「外的ショック」への対応力に限界があります。例えば、新型コロナ禍のような突然の需要変動には脆弱です。そのため、データを事前に検証し、残差分析(residual analysis)でモデル適合度を確認することが不可欠です。
回帰分析による多因子予測
単純な売上推定ではなく、「価格」「広告費」「季節要因」など複数の外部変数と関連づけた需要を予測したい場合に有効なのが重回帰分析(Multiple Linear Regression)です。この方法では、販売データがどの程度「価格低下」と「広告投入量」によって影響を受けているかを数量的に評価できます。
例えば、120円の価格で3万件売れた商品と、98円での5万件販売データがあれば、「単位コストが1%低下すると需要は平均して4.7%増加する」といった経済的感度を算出可能です。
以下が実装例です。まずpandasで複数の説明変数(価格・広告費)と目的変数(売上)を集約し、統計モデルライブラリstatsmodelsを使って回帰分析を実行します。
import pandas as pd
import statsmodels.api as sm
# サンプルデータ(過去の販売数、価格、広告費)
data = {
'sales': [120, 130, 125, 140, 150, 160, 155, 170, 165, 175],
'price': [10, 10, 11, 11, 12, 12, 11, 11, 12, 12],
'ad_spend': [200, 220, 210, 230, 240, 250, 240, 260, 255, 270]
}
# データをPandasのデータフレームに変換
df = pd.DataFrame(data)
# 目的変数と説明変数を分離
X = df[['price', 'ad_spend']]
y = df['sales']
# 定数項(切片)の追加
X = sm.add_constant(X)
# 回帰モデルを適用してフィッティング
model = sm.OLS(y, X).fit()
# 結果の要約表示(回帰係数、p値、R2など)
print(model.summary())
# 新しい条件での予測:価格11円・広告費250万円の場合
new_data = {'price': [11], 'ad_spend': [250]}
new_df = pd.DataFrame(new_data)
new_df = sm.add_constant(new_df)
forecast = model.predict(new_df)
print(forecast)出力結果の一部を示します。
OLS Regression Results
==============================================================================
Dep. Variable: sales R-squared: 0.964
Model: OLS Adj. R-squared: 0.958
Method: Least Squares F-statistic: 172.3
Date: Mon, 01 Jan 2024 Prob (F-statistic): 6.7e-08
この結果から、R²(決定係数)が96.4%という高い値を示しており、「価格」と「広告費」の組み合わせで売上データの変動の約96%が説明可能であると判断できます。また、p値は0.05未満なので、両因子とも統計的に有意です。
予測結果として「価格11円・広告費250万円」の条件下で売上が[167.8]と推定されました。この数値は実際のデータ(例:前回=170)に近いため、モデルが有効であると考えられます。
注意点として、「説明変数同士の相関性」や「外れ値」といった要因を無視すると誤った結論が出ます。特に広告費と売上の因果関係は、他社との競争状況や季節要因によって左右されるため、単純に回帰係数だけで判断しないようにしましょう。
モデルの評価指標:MAE, RMSE, MAPEで精度を可視化
どの予測手法も「正解」が存在しないため、信頼できるモデルとはどれだけ誤差が少ないかという点に注目する必要があります。以下の指標は一般的な評価基準です。
- MAE(平均絶対誤差):予測値と実際の売上の「絶対誤差」を平均した数。単位がそのまま保持されるため解釈しやすい。
- RMSE(平方根平均二乗誤差):大きい誤差に重みを与えるため、外れ値への敏感度が高い。
- MAPE(平均絶対誤差率):相対的な誤差を表示。売上10万円の商品と1,000円の商品で比較可能だが、実測値がゼロだと無限大になる点に注意。
一般的な目安として:MAE とされています。ただし用途によって基準は変動します。
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
# 実際の販売データと予測値(例)
actual_sales = [160, 165, 170, 175, 180]
predicted_sales = [162.3, 164.9, 172.5, 174.8, 183.2]
# MAEの計算
mae = mean_absolute_error(actual_sales, predicted_sales)
print(f'MAE: {mae:.2f}')
# RMSEの計算
rmse = np.sqrt(mean_squared_error(actual_sales, predicted_sales))
print(f'RMSE: {rmse:.2f}')
# MAPE(絶対誤差率)を算出
mape = np.mean(np.abs((np.array(actual_sales) - np.array(predicted_sales)) / np.array(actual_sales))) * 100
print(f'MAPE: {mape:.2f}%')実行結果:
MAE: 1.98
RMSE: 2.67
MAPE: 1.42%
このモデルは、平均して約2単位の誤差で推定できており、MAPEが1.42%と非常に低い結果です。これは実用的な予測精度を満たしていると言えます。
評価指標を使い分けることで、「外れ値に強いモデルが必要か」「単位の大きさに関係なく比較したいのか」などの判断が可能になります。需要予測は「完璧な結果を得ること」ではなく、「誤差を最小限に抑えながら、経営意思決定を支えることです。
最後の注意点として:データの前処理(欠損値補完・外れ値除去)やモデル選定では「過学習」が起きやすい。交差検証(Cross-validation)を用いて、訓練データとテストデータで性能を比較することが重要です。